
Die Themen Semantik und vernetztes Wissen rücken in der Technischen Redaktion immer stärker in den Fokus. Doch was versteht man in diesem Zusammenhang unter „Semantik“ und welchen Mehrwert bietet der Einsatz semantischer Technologien?
Wir alle kennen das: Auf Basis einer einfachen Suchanfrage im Internet erhalten wir auch Ergebnisse, die wir im Zusammenhang mit unserer Anfrage nicht erwartet haben. Diese Ergebnisse werden meist von intelligenten Informationssystemen geliefert, die vernetztes Wissen generieren.
Solche Systeme, bzw. die dahinterliegende Technologie, kommen auch vermehrt in der Technischen Redaktion zum Einsatz.
Die Intelligenz dieser Systeme beruht auf zwei Dingen:
- der Semantik, der Lehre von der „Bedeutung“ (methodische Basis),
- gepaart mit einer spezifischen Art von Datenbank (technologische Basis).
Wie beschreiben wir Inhalte auf herkömmliche Weise?
Redaktionssysteme arbeiten in der Regel mit Metadaten. Metadaten sind quasi das Etikett am Modul, mit dem der Inhalt beschrieben wird.
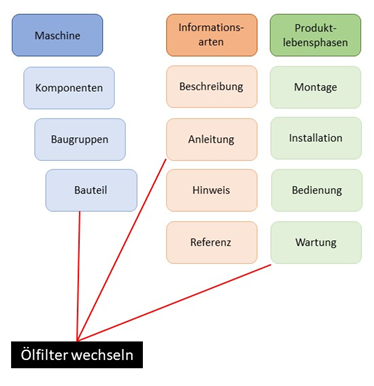
Beispiel: Ölfilter an einer Maschine wechseln.
Die Informationseinheit „Ölfilter wechseln“ wird mit Metadaten verschlagwortet (in der Abbildung vereinfacht dargestellt mit Bauteil = Ölfilter / Informationsart = Anleitung / Produktlebensphase = Wartung).
Damit sind wir nicht nur in der Lage, die einzelne Informationseinheit zielsicher in der Gesamtheit aller Module zu finden, sondern sie auch für andere Zwecke zu nutzen, z. B. zum Filtern von Varianten. Ein Metadatenkonzept ist also ein wesentliches Element bei der Arbeit mit Redaktionssystemen.
Jedoch enthalten Informationseinheiten viele einzelne Inhalte, die sich nur durch großen manuellen Aufwand als Metadaten abbilden lassen. Auf unser Beispiel bezogen bedeutet das: Wartungsintervalle, Technische Daten, benötigte Werkzeuge, Fehlerursachen und eine Vielzahl anderer, wichtiger Informationen im Inhalt des Moduls „Ölfilter wechseln“ müssten manuell über eine ebenso große Anzahl von Metadatenstrukturen erfasst werden.
Die herkömmliche Art der Metadaten-Verschlagwortung ermöglicht zwar den maschinenlesbaren Zugriff auf einzelne (ganze) Informationseinheiten, maschineninterpretierbar wird der Inhalt dadurch jedoch nicht.
CCMS basierend auf semantischer Technologie
Einen großen Schritt weiter gehen sogenannte vollsemantische CCMS, die mit sogenannten „Knowledge Graphen“ arbeiten, einer Technologie aus dem Bereich der künstlichen Intelligenz.
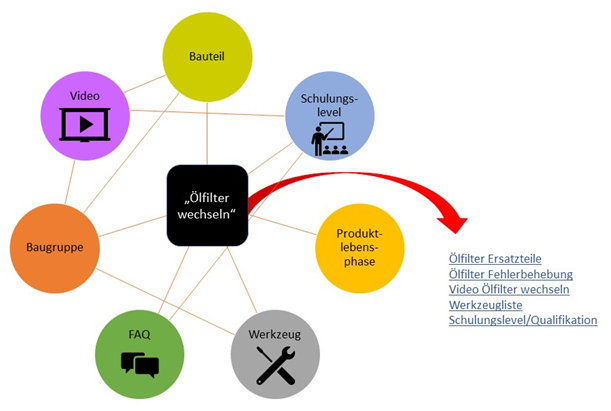
Knowledge Graph
In Knowledge Graphen werden alle Informationen entsprechend ihrer Gültigkeit einzelnen Netzknoten zugeordnet, die vielfältige Beziehungen untereinander haben können. Durch entsprechende Befüllung der Datenbasis entsteht so mit der Zeit eine wachsende Struktur von Informationen und Gültigkeiten.
Aus der Fülle dieser Daten und Beziehungen können die auf semantischer Technologie basierenden CCMS die Bedeutung bestimmter Inhalte erkennen, sie interpretieren und quasi logische Schlussfolgerungen ziehen, die bei entsprechender Abfrage auch zu neuen Zusammenhängen und Ergebnissen führen, z. B.:
„Ölfilter warten“ » weitere Ergebnisse
- Ölfilter Ersatzteile
- Ölfilter Fehlerbeseitigung
- Video Ölfilter wechseln
- Werkzeugliste
- Schulungslevel/Qualifikation
Vorteile vollsemantischer CCMS
Die Möglichkeit zur Nutzung von Content Delivery Portalen stellt für Anwender eine Große Hilfe dar. Wenn die Inhalte in diesen Portalen dazu noch so aufgebaut sind, dass Suchanfragen eine große Anzahl sinnvoller Ergebnisse liefern, ist der Mehrwert auch für den Anwender entsprechend höher.
Darüber hinaus gewinnt auch die Digitalisierung im Bereich Service und Instandhaltung zunehmend an Bedeutung. Bei der Vernetzung von Maschinen mit Informationen ist vielleicht nicht das gesamte Topic relevant, sondern nur der Verweis auf einen einzelnen Parameter, einen Fehlercode oder ein spezifisches Werkzeug einer bestimmten Größe. Vollsemantische CCMS bieten die Möglichkeit, die Inhalte von Informationseinheiten auszuwerten und darzustellen.
Semantik mit GRIPS der STAR AG nun auch bei tecteam
Eines dieser vollsemantischen CCMS ist GRIPS der STAR AG.
GRIPS verzichtet beispielsweise komplett auf die manuelle Erfassung von Metadaten, stattdessen setzt diese automatisch, allein durch die Platzierung einer Informationseinheit auf einen bestimmten Matrixknoten. Dadurch ist alles, was im Inhalt nicht vorhanden ist, wie beispielsweise der Bezug zu einer Baugruppe, einer Variante oder einer Informationsart, bereits semantisch erfasst und muss nicht durch Metadaten beschrieben werden. Hingegen werden alle Kerninhalte der Informationseinheit (Werkzeuge, Materialien, Qualifikationen, etc.) durch Verknüpfungen mit dem Inhalt referenziert.
GRIPS ist bei tecteam bereits seit vielen Jahren im Einsatz, das Knowhow der Mitarbeiterinnen und Mitarbeiter daher entsprechend groß.
Seit tecteam und die STAR AG gemeinsam bei einem namhaften Staatsunternehmen GRIPS eingeführt haben, wurde der beiderseitige Wunsch nach einer Kooperationspartnerschaft laut. Seit kurzem ist diese Partnerschaft besiegelt.
tecteam kann damit sein Beratungsportfolio um das Thema „Semantik“ ergänzen. Eine Technologie, welche bereits heute viele Fachleute umtreibt, und mit Sicherheit auch die Zukunft der Technischen Dokumentation/Kommunikation entscheidend prägen wird.





Hinterlasse einen Kommentar